Facebook provides a Like Box to show on your Website, what’s going on on your facebook page.
A nice way to show this box is by a simple tab on the left or right which (on mouseover) slides in this box.
Here’s an easy script to implement this on your page.
Following steps are needed to implement this:
1. Upload the Images for the Facebook Text-Logo
Image Left
Image Right
2. Add the jQuery Script to your page
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js"></script>
3. Add the CSS Styles
<style type='text/css'>
/*<![CDATA[*/
#fbplikebox {
display: block;
padding: 0;
z-index: 99999;
position: fixed;
}
.fbplbadgeright {
background-color:#3B5998;
display: block;
height: 150px;
top: 50%;
margin-top: -75px;
position: absolute;
left: -47px;
width: 47px;
background-image: url('fbtext_right.png');
background-repeat: no-repeat;
overflow: hidden;
-webkit-border-top-left-radius: 8px;
-webkit-border-bottom-left-radius: 8px;
-moz-border-radius-topleft: 8px;
-moz-border-radius-bottomleft: 8px;
border-top-left-radius: 8px;
border-bottom-left-radius: 8px;
}
.fbplbadgeleft {
background-color:#3B5998;
display: block;
height: 150px;
top: 50%;
margin-top: -75px;
position: absolute;
right: -47px;
width: 47px;
background-image: url('fbtext_left.png');
background-repeat: no-repeat;
overflow: hidden;
-webkit-border-top-right-radius: 8px;
-webkit-border-bottom-right-radius: 8px;
-moz-border-radius-topright: 8px;
-moz-border-radius-bottomright: 8px;
border-top-right-radius: 8px;
border-bottom-right-radius: 8px;
}
/*]]>*/
</style>
4. Add the Javascript
<script type='text/javascript'>
/*<![CDATA[*/
(function(w2b){
w2b(document).ready(function(){
var fromRight = false;
var topPosition = 50;
var logoPosition = 150;
var elementWidth = 292;
var $dur = 'medium';
// Set the Tab Position
$("#fbplikeboxlogo").css("top", logoPosition);
if (fromRight) {
$("#fbplikeboxlogo").addClass("fbplbadgeright");
w2b('#fbplikebox').css({right: -elementWidth, 'top' : topPosition })
w2b('#fbplikebox').hover(function () {
w2b(this).stop().animate({
right: 0
}, $dur);
}, function () {
w2b(this).stop().animate({
right: -elementWidth
}, $dur);
});
} else {
$("#fbplikeboxlogo").addClass("fbplbadgeleft");
w2b('#fbplikebox').css({left: -elementWidth, 'top' : topPosition })
w2b('#fbplikebox').hover(function () {
w2b(this).stop().animate({
left: 0
}, $dur);
}, function () {
w2b(this).stop().animate({
left: -elementWidth
}, $dur);
});
}
w2b('#fbplikebox').show();
});
})(jQuery);
/*]]>*/
</script>
5. Add the Content
<div id='fbplikebox' style='display:none;'>
<div id='fbplikeboxlogo'></div>
<iframe src="http://www.facebook.com/plugins/likebox.php?href=https%3A%2F%2Fwww.facebook.com%2FFacebookDevelopers&width=292&height=590&colorscheme=light&show_faces=true&header=true&stream=true&show_border=true" scrolling="no" frameborder="0" style="border:none; overflow:hidden; width:292px; height:590px; background:#FFFFFF;" allowTransparency="true"></iframe>
</div>
There you go, that is all. Here’s a working examle:
facebookslide
There are some configuration variables at the top of the javascript:
| Name |
Function |
| fromRight |
Defines if the tab is on the left or on the right |
| topPosition |
The space from the top of the page before the box starts |
| logoPosition |
The space from the top where the tab appears |
| elementWidth |
The width of the facebook box |
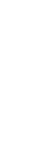{kind=link}
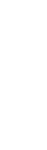{kind=link}